Scheduling Messages In A Pub/Sub Pattern (1)
Around 6 years ago, we started to improve our User Experience implementing new ways to process heavy tasks in a asyncronous way so our users wouldn't be affected waiting for an image to be processed or an email to be sent while visiting our sites. We could achieve that applying the Publish-subscribe (opens new window) messaging pattern, so all the heavy or none critical tasks could be executed in a different process improving not only the UX, also the server capacity and the load control.
But some time afer we sucessfully build the system, a new requirement was thrown:
_we want to schedule the produced messages to be consumed later_.
Why later? Because some use cases require to schedule actions to be triggered in the future.
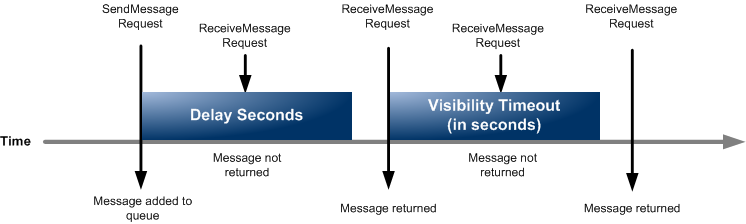
So, as our infrastructure stack is based on AWS and our workers are consuming messages from SQS queues, one possible solution could be send messages to the queue indicating the DelaySeconds (opens new window) value.
However we got a limitation. As you may know, the max value is 15 minutes and it was not enougth for us because we wanted to delay the consumption of a message for days, if necessary.
We needed to find or build something that could be able to retain the messages to be published later. A man in the middle between the producers and consumers that could receive the messages, store and deliver them to a specific destination at the scheduled time.
# Starting with a POC
To find a proper solution, a small team started to investigate possible available tools that would fit in our use case but as nothing useful was found, the team started to prepare a POC using golang and Redis as storage. It was one of the very first projects built with go in the company, at that time we were running golang 1.6 using glide as a dependency manager and redis 3.2.
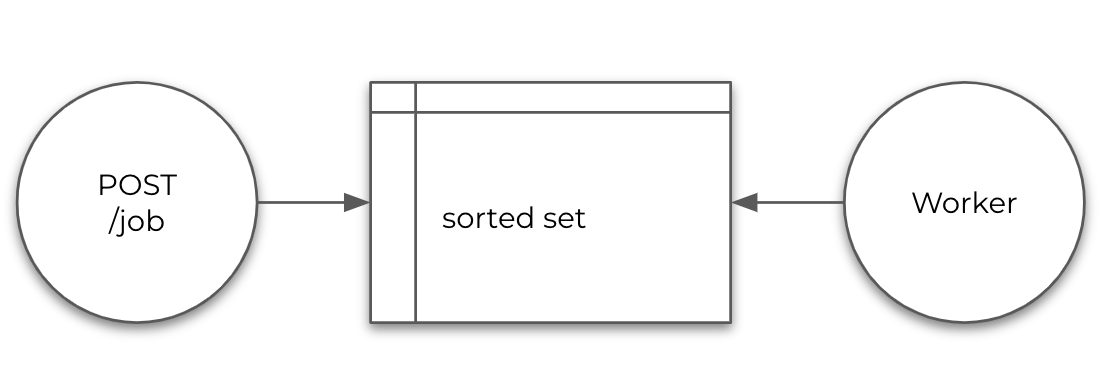
The idea was simple, one single binary with two processes:
- A REST API server to receive, validate and store messages in a sorted set (opens new window) using the schedule time (unix timestamp) as
score. - A Worker that would pull data, get the due time items and deliver them to a specific destination.
The first iteration worked great, but we found a couple of issues:
- If the Sorted Set Score is based on a timestamp, what happens if we need to store two or more messages that need to be delivered at the same time?
Not a problem, redis can handle elements with the same score (opens new window)
- What happens if there are two or more worker processes pulling data from the Sorted Set at the same time?
In redis 3.2 we didn't have the ZMPOP (opens new window) command that could be really useful popping the elements by score and returning the values.
To achieve the same result the solution was to execute a LUA script embedded in redis:
local jobs = redis.call("ZRANGEBYSCORE", KEYS[1], "-inf", ARGV[1], "LIMIT", ARGV[2], ARGV[3])
if #jobs > 0 then
redis.call("ZREM", KEYS[1], unpack(jobs))
end
return jobs
This script was executed atomically so no other processes couldn't retrieve the same items. This means that we were blocking the Sorted Set for a while.
# Running in production
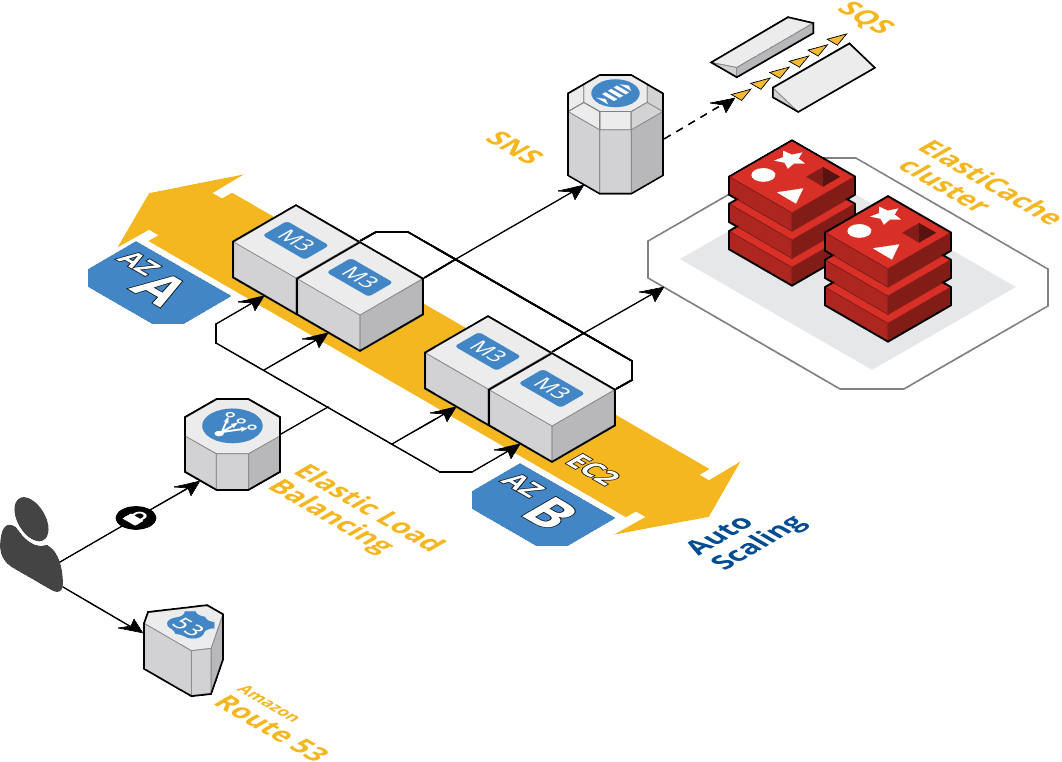
During all these years we have been only upgrading the golang and redis versions, but most of the code has never been touched, even the LUA script!
The service was composed of two t3a.medium EC2 instances and a cache.m6g.large redis cluster 6.0.5 processing more than 5 million messages a day (~65 req/sec) and even when it has been running uninterruptedly, we have identified some things that could be improved:
- Reliability: the model was not fully reliable. For example, at the same time that the data was retrieved from the storage it was also deleted. So, in case of failure, the processing data would be lost.
- Durability: elastic cache storage is limited and once de message was processed, the data disappeared.
- Traceability: there was lack of information about the state of each schedule and delivery. It means that if the message was retried or failed, it was very difficult to debug issues.
- Maintenance: maintaining this kind of infrastructure suposed to perform some tedious tasks like managing SSL certificates, autoscaling groups, storage (in memory) consumption, upgrading instances and clusters.
- Centralization: the service was serving all the products in the company so, if something failed during an upgrade, all the products would be affected.
In addition, there were some functional limitations that we wanted to solve like cancel (or remove) scheduled messages before the due date or reschedule them.
# A new Message Scheduler was born
For all those reasons, we have been working in a new service version that covers all the missing parts and improves the overall experience for devs and ops offering a different approach when using the service.
We are happy to explain you all the details on the next post!